
예텐보리 대학의 Robert Lowe그룹은 인지적으로 까다로운 작업에서 감정 표정의 역할을 연구해 왔으며 그들의 초점은 감정 표정이 다음을 안내하는지 여부와 방법에 있었습니다.
- 상호적 가치학습, 그리고
- 상호적 시정 조치 선택
연구자들은 차등적 결과 학습 패러다임과 시정 조치 선택이 필요한 대화형 지도 탐색 작업에 대한 다양한 사회적 상호 작용 기반 연구를 수행했습니다. 연구자들의 더 넓은 관심은 공동 활동에서 감정을 사용하는 것에 관한 것입니다.
차등적 결과 학습
Rittmo et al. (2020)이 최근 발표한 기사에서 연구자들은 기존의 심리학(학습 패러다임)의 반응 지식 전달을 위한 차등적 결과 학습을 적용했습니다. 차등적 결과 훈련은 임의의 자극(예: 컴퓨터 작업의 우산 이미지)에 이어 다른 반응 옵션(예: 누를 좌우 반응 탭)이 이어지는 고전적인 자극-반응 훈련 설정에서 활용되며, 여기서 오직 하나의 반응만이 '올바른' 피드백을 제공합니다. 학습은 시행착오에 의한 것입니다. 참가자들은 보상적이거나 강화된 결과(예: 돈 이미지)를 얻기 위해 다양한 자극을 다양한 반응 옵션과 일치시켜야 합니다.
표준 행동 학습 접근법과 달리, 차등 결과 훈련은 상이한 자극-반응 쌍을 수반하고 차등적인 보상 결과(예: 큰 보상 대 낮은 보상)가 뒤따릅니다. 차등 대 비차등(모든 올바른 반응에 대한 동일한 보상) 결과 훈련 하에서 더 빠른 학습이라는 차등 결과 효과는 이 실험 설정을 사용한 연구(McCormack et al. 2019)에서 안정적으로 발견되었습니다.
표현된 감정으로부터 상호작용적 가치 학습
예테보리 대학(Gothenburg University)의 연구원들은 사회적 환경에서 컴퓨터화된 작업의 형태로 차등적 결과 절차의 새로운 변형을 수행했습니다. 이것은 참가자들이 높거나 낮은 보상을 받은 도구적 반응(각각 큰돈 또는 작은 돈의 이미지)을 따라 긍정적인 감정과 부정적인 감정을 표현하는 여배우(연합)의 비디오를 통해 배워야 하는 것을 요구했습니다.
여기서 부정적 감정은 앞서 제시된 자극에 대한 올바른 반응에 따라 상대적으로 낮은 보상결과에 대한 가벼운 좌절감의 표현하는 역할을 했습니다.
시각적 자극과 반응 옵션 간의 연관성
실험에서 참가자들은 처음에 시각적 자극과 서로 다른 쌍의 다른 가치(보상) 결과(높은 현금 보상과 낮은 현금 보상의 이미지)를 가져온 반응 옵션 사이의 연관성을 학습해야 했습니다. 그런 다음 참가자들은 동일한 작업에 참여하지만 새로운 시각적 자극이 제시된 연맹을 관찰해야 했습니다.
따라서 초기 훈련에서는 자극에 빗자루의 이미지(컴퓨터 화면)를 포함한 반면, 관찰 훈련에서는 버스의 이미지가 제시될 수 있습니다. 아래에서 초기 훈련의 시험 진행도를 볼 수 있습니다.
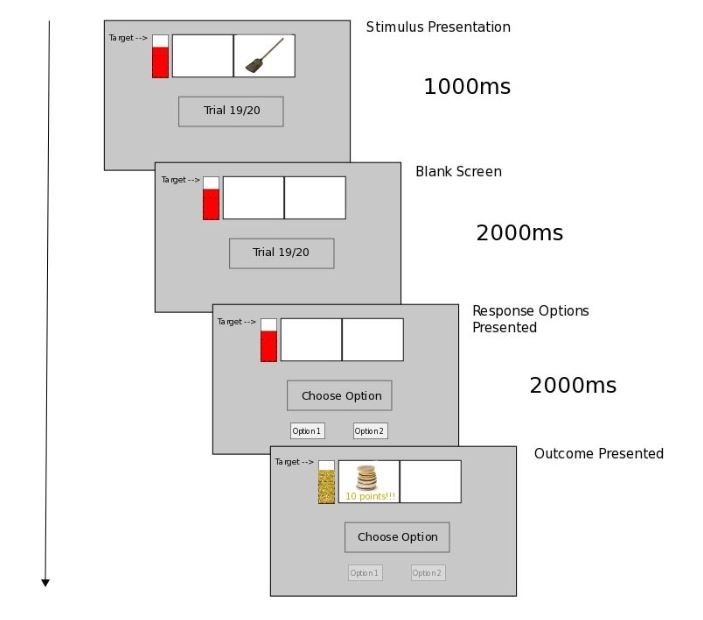
관찰 훈련에서는 초기 훈련과 마찬가지로 실험이 진행되었지만 , 이제는 실험 내내 여배우의 영상이 재생되는 동안 관찰 참가자의 시야에서 반응 옵션이 가려졌습니다.
결과 발표될때(관찰 참가자의 시야에도 숨겨져 있음) 여배우는 아래와 같이 가벼운 좌절감을 표현하기 위해 미소를 지을 것입니다.
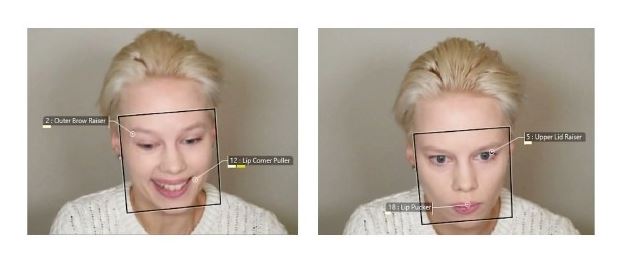
여배우는 자연스럽게 감정을 표현하도록 지시를 받았습니다. FaceReader는 관찰 훈련에 사용된 20개의 연속적인 실험에 대해 평가했을 때 신뢰할 수 있는 것으로 나타난 표현의 정서가에 대한 다루기 쉬한 정도를 평가하는 데 사용되었습니다. 이러한 방식으로 표현된 감정은 참가자가 잠재적으로 배울 수 있는 높고 낮은 가치의 결과에 대한 프록시 역할을 했습니다.
연관성 2-프로세스 이론
Rittmo et al. (2020)의 실험은 초기 훈련, 관찰 훈련부터 실험 단계까지 참가자들의 상호 작용적 가치 학습을 평가했습니다. 이 실험 단계에서는 여배우가 특정한 새로운 자극에 반응하는 것을 본 적이 없음에도 불구하고 (사실 그녀는 반응을 선택하지 않고 비디오 설정에 반응했을 뿐) 여배우가 '선택한' 반응을 선택하는 경향이 있는 참가자들에 대한 반응 옵션이 다시 표시되었습니다.
Lowe et al. (2016)에 기초하여, 참가자 실험 단계 반응 선택은 연관성 2-프로세스 이론(Trapold 1970, Urcuioli 2005)의 수정된 (사회적) 버전에 따라 예측되었습니다. 실험과 관련하여 고전적인 연관성 2-프로세스는 아래에 도식화되어 있습니다.
맨 위 행에는 시행 절차가 표시됩니다. 단계 1에서는 제시된 주어진 자극(예: S1 다음의 R1, 이 실험에서는 R2가 ‘잘못됨')에 대한 올바른 반응과 그에 따른 보상 결과(S1->R1 페어링의 경우 O1)를 볼 수 있으며, 잘못된 반응을 선택했을 때 보상이 없거나 처벌적인 결과가 표시됩니다. (예: S1->R2->처벌).
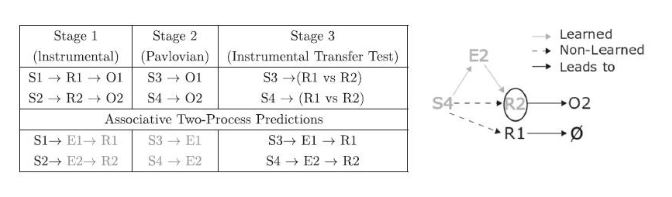
실험의 각 단계에서는 다양한 자극(S1, S2, S3, S4) 및 반응(R1, R2) 옵션이 여러 번의 시도에 걸쳐 (시도당 하나의 자극)에 걸쳐 제시됩니다. 1단계와 3단계에서는 모두 반응 옵션이 제시되고(위의 스키마와 일치) '올바른' 반응은 보상적인 결과(O1 또는 O2)로 이어지며 그렇지 않으면 보상이 없습니다.
기대 형성
연관 2-프로세스 이론은 참가자들이 각각 높은 보상(O1)과 낮은 보상 (O2)에 대해 서로 다른 결과 (E1, E2)에 대한 기대 (가치)를 형성한다고 예측합니다. 이러한 기대는 (외부) 자극과 반응 모두와 연관될 수 있는 내부 자극의 역할을 합니다. 이러한 방식으로, 참가자들은 예를 들어, E2가 R2 (1단계)와 S4 (2단계)와 연관되었다는 것을 배울 수 있습니다.
따라서, S4가 3단계에서 다시 제시되면 E2의 표현을 연관적으로 신호하고 이는 다시 R2의 표현을 연관적으로 신호해야 합니다. 이와 같이, 참가자들은 S4-R2 페어링으로 동일한 실험에서 제시된 적이 없음에도 불구하고 특정 반응(R2)에 편향됩니다
사회적 연관성 2-프로세스 학습
Lowe et al.(2016)에서는 공동활동에서 다른 사람과 경쟁하지 않는 참가자들은 "다른 사람의 입장에 서서" 마치 자신의 것처럼 다른 사람의 가치기반 결과기대(높은 보상 대 낮은 보상)를 자신의 것처럼 학습할 것이라는 가설이 제시되어 있는데, 이를 대리 가치 학습이라고 합니다.
이는 위에서 언급한 3단계 설정을 적응한 것으로 2단계의 고전적 설정에서, 참가자들은 제시된 각 새로운 자극(파블로브 조건화)에 대한 차등적인 결과를 인식합니다. 대신, Rittmo et al. (2020)의 참가자들은 실제(현재는 보이지 않는) 결과에 대한 대용으로 동맹의 감정 표현을 관찰합니다.
이 사회적 연관성 2-프로세스는 참가자들이 2단계에서 새로운 자극을 마치 연합의 자리에 존재하는 것처럼 평가한다는 가설을 설정합니다. 그런 다음 참가자들은 업데이트된 자극 평가를 사용하여 위에서 논의한 연관 경과 추론을 사용하여 반응을 선택했습니다(그림에서 연관 경과 추론에 의해 S4->E2, E2->R2는 S4->R2를 제공함).
불완전한 정보(즉, 상대방의 반응이 보이지 않음)를 기반으로 하는 이러한 대화형 가치 학습은 상호 작용하는 에이전트가 '빠른 실행' 작업에 대해 협력해야 하는 공동 활동 동안 유용할 수 있습니다. 다른 에이전트의 작업이 어떻게 진행되고 있는지에 대한 정보를 전송하는 감정 신호는 오랜 시행착오 학습 과정을 우회하는 수단을 제공할 수 있습니다.
이것은 특히 차등적 감정 상태(결과 기대)가 작업 관련 자극에 대한 공통 클래스를 구성하는 상황, 즉 특정 자극 그룹이 일반적으로 특정 유형의 반응을 유발하는 상황에서 적용되어야 합니다.
감정은 교정반응을 안내
공동 활동 중에 다른 사람의 수행을 관찰하는 또 다른 측면은 다른 사람을 모니터링하고 시정 대응을 하는 것과 관련이 있습니다. 즉 예상치 못한 일이 발생했을 때 협력 작업 중에 보상적인 대응을 제공하는 것입니다. 그러한 경우 감정은 교정 반응을 안내한다고 합니다. (Oately & Johnson-Laird, 1987, 2014).
Borges et al. (2019)은 예테보리 대학에서 수집한 비디오 데이터 세트를 사용했으며, 지도 탐색 작업에 참여하는 교수자-팔로워 쌍으로 구성되었습니다. 이 작업은 교정 응답(예: 질문, 확인문)에 필요한 교수자와 팔로워 사이의 잘못된 의사소통을 유도하기 위해 설계되었습니다. 아래에는 한 참가자가 다른 참가자를 관찰하고 청각적으로 의사소통할 수 있는 상호 작용의 예가 제시되어 있습니다.(FaceReader8.0을 사용하여 분석하였습니다.)
그러나 DICE 연구소 연구 그룹의 연구의 초점은 비디오에서 혼란스러운 표정 상태를 분류하기 위한 신경망(Long-Short-Term Memory/LSTM) 교육에 있었습니다.
FaceReader 소프트웨어 내에서 혼란은 정서적 태도('지루함', '관심'과 함께)로 간주되지만, 이는 구성 요소가 보편적으로 수용되지 않고 특정 작업에 국한될 수 있는 정서적 상태입니다.
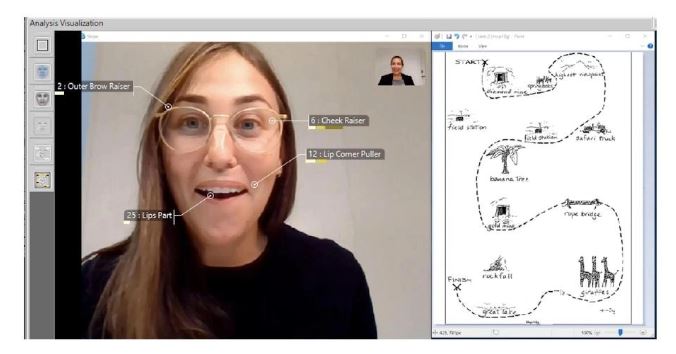
정서적 태도 혼란
감정의 얼굴 표현을 처리하여 혼란스러운 상태를 자동으로 감지하고 상대적으로 빠르게 처리할 수 있다는 이점은 인간-컴퓨터 상호 작용에 대한 연구에서 분명하게 드러납니다. (Lago & Guarin, 2014). 예를 들어, 인간 참가자의 혼란이 소프트웨어 에이전트에 의해 감지되면, 주체가 활동에서 벗어나기 전에 에이전트는 혼란을 해결하기 위한 응답을 수행할 수 있습니다. 이것은 인간-컴퓨터 상호작용 작업의 공동 활동부터 게임 및 인지 작업의 게임화에 이르기까지 잠재적으로 많은 응용 분야를 가지고 있습니다.
Borges et al. (2019)에서, 우리는 FaceReader 분석 비디오에서 액션 단위 입력에 대해 LSTM을 교육하고 긍정적, 부정적, 중립 및 혼란 감정 상태에 대한 기준 진실값(평가자 간 코딩)을 기준으로 상당한 분류 정확도, 정밀성 및 재현율을 도출하였습니다.
이 작업은 로봇이 다른 사람(Rittmo et al., 2020에서와 같이)으로부터 대리 학습하는 동시에 공동 활동에서 벗어날 수 있는 다른 사람의 정서적 상태(예를 들어 ‘혼란’으로 표시됨)에 반응하도록 요구하는 인간-로봇 상호 작용 작업(Lowe et al., 2019)의 맥락에서 유망하다고 생각합니다.
References
Borges, N.; Lindblom, L.; Clarke, B.; Gander, A. & Lowe, R. (2019). Classifying confusion: Autodetection of communicative misunderstandings using facial action units. 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), 401–406. IEEE. https://doi.org/10.1109/ACIIW.2019.8925037.
Lago, P. & Guarin, C.J. (2014). An affective inference model based on facial expression analysis,” IEEE Latin America Transactions, 12(3), 423–429. https://doi.org/10.1109/TLA.2014.6827868.
Lowe, R.; Almér, A.; Gander, P. & Balkenius, C. (2019). Vicarious value learning and inference in human-human and human-robot interaction. 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), 395–400. IEEE. https://doi.org/10.1109/ACIIW.2019.8925235.
Lowe, R.; Almér, A.; Lindblad, G.; Gander, P.; Michael, J. & Vesper, C. (2016). Minimalist social-affective value for use in joint action: A neural-computational hypothesis. Frontiers in Computational Neuroscience, 10, 88. https://doi.org/10.3389/fncom.2016.00088.
McCormack, J. C., Elliffe, D. & Virués‐Ortega, J. (2019). Quantifying the effects of the differential outcomes procedure in humans: A systematic review and a meta‐analysis. Journal of applied behavior analysis, 52(3), 870-892. https://doi.org/10.1002/jaba.578.
Noldus. (2019). FaceReader: Tool for automatic analysis of facial expression, Version 8.0 [Software]. Wageningen, The Netherlands: Noldus Information Technology B.V.
Oatley, K. & Johnson-Laird, P.N. (1987). Towards a cognitive theory of emotions. Cognition and emotion, 1(1), 29-50. https://doi.org/10.1080/02699938708408362.
Oatley, K. & Johnson-Laird, P.N. (2014). Cognitive approaches to emotions. Trends in cognitive sciences, 18(3), 134-140. https://doi.org/10.1016/j.tics.2013.12.004.
Rittmo, J.; Carlsson, R.; Gander, P. & Lowe, R. (2020). Vicarious Value Learning: Knowledge transfer through affective processing on a social differential outcomes task. Acta Psychologica, 209, 103134. https://doi.org/10.1016/j.actpsy.2020.103134.
Trapold, M.A. (1970). Are expectancies based upon different positive reinforcing events discriminably different? Learning and Motivation, 1, 129–140. https://doi.org/10.1016/0023-9690(70)90079-2.
Urcuioli, P.J. (2005). Behavioral and associative effects of differential outcomes in discrimination learning. Animal Learning & Behavior, 33, 1–21. https://doi.org/10.3758/BF03196047.
원문
https://www.noldus.com/blog/role-facial-expression-emotion-joint-activities
'행동관찰분석 > 리서치 사례' 카테고리의 다른 글
| 투자자 프레젠테이션 중 기업가의 표정과 감정의 전염 (0) | 2023.11.08 |
|---|---|
| 파킨슨병 환자는 감정을 어떻게 표현하는가 (0) | 2023.11.02 |
| 감정을 관리하는 능력이 위험에 대한 인식을 어떻게 형성하는가 (0) | 2023.09.25 |
| 광고에서 유발되는 감정이 브랜드 태도에 미치는 영향 (0) | 2023.09.21 |
| 정치광고 영상에 대한 감정적 반응의 강도 측정 (1) | 2023.09.18 |